
昨年からぼちぼちと機械学習による競馬予想モデルを作っていたのですが、その予想モデルの単勝回収率が100%超えちゃったかもな話です。
機械学習予想モデルの概要
使用するデータは?
まずはデータ何使っているの? ですが、
当初はタダでデータを集めたかったので、ネット競馬のWEBページをPythonでスクレイピングしていたんですけど、のちのちあのデータもほしい、アレの検証もしたい・・・、となるといちいちスクレイピングし直してデータを取ってくるのはめんどくさくなりまして。。。
スクレイピングってものすごく時間かかりますしね。サイトに負荷をかけないようにスリープ(待機時間)をかけて1ページずつ取得しなければならないわけで。
データ取るだけで丸一日かかってしまうのはちょっとなぁ・・・ってなりまして、JAR-VANに課金し、データをそこから引っ張ってくる事にしました。
JAR-VANは月2000円かかりますが、スクレイピング待ちのストレスを考えれば安いもんですねぇ。
あと、WEBからスクレイピングしたデータはゴミが混ざっていたりして、データをクレンジングする必要があり、それが手間で手間で仕方なかったですし(;´Д`)
ただ、そのJRA-VANですが、登録課金しただけではそのデータを扱えません。(データにアクセスするソフトを自作すればいけますが・・・)
第三者が作っている専用ソフトをダウンロードするとデータを簡単に扱うことが出来るようになります。
そのソフト選びも重要なんですけど、私的に使い勝手が良いなと思うのは
TARGET frontier JV と PC-KEIBA Database この2つかなと
TARGET frontier JVについてはJRA-VANデータラボの公式ソフトなんじゃね?ってくらいポピュラーなソフトで、このソフト単体で競馬予想、分析ができてしまいます。
でも私はソフト上での分析よりもPythonで機械学習、データ分析をやりたいので、そのためにはソフトから一旦データをcsvでエクスポートしなければならず、それが結構煩わしい。
で、機械学習に必要な最低限のデータをTARGET frontier JVで取得し、主要なデータ(競走馬、種牡馬マスタ、レース、オッズ情報など)はPC-KEIBA Databaseで作成されたPostgreデータベースにアクセスして都度取得するという形をとっています。
いや~、PC-KEIBA Databaseは神ソフトですね。(あくまで私にとっては、です)
PC-KEIBA DatabaseはJRA-VANのデータをダウンロードして、そのデータのデータベースをPC内に構築してくれるんですよね。データの更新もやってくれるので、常に最新の競馬データベースが自分のPCの中にできちゃうわけです。(自分でやろうとしたらめちゃくちゃ大変だと思われ)
んで、あとはPythonのスクリプトで欲しいデータをデータベースから引っ張ってきて、そのまんま分析。
欲しいデータにすぐアクセスできるのでマジ最高。
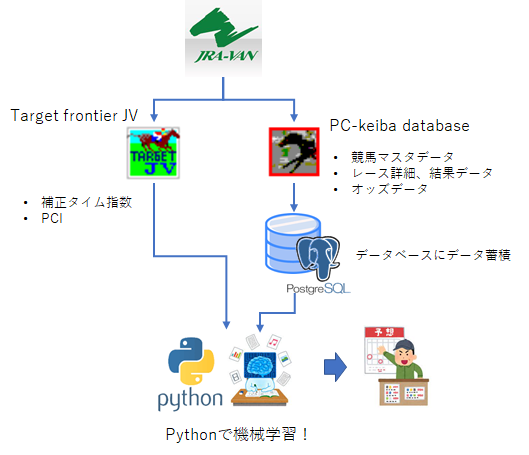
特徴量は何使ってんの?
機械学習の特徴量とは対象、目的となるデータの特徴を数値で表したものです。
例えば目的となる値、知りたい情報を家賃とした場合、その家賃を表す特徴量としては築年数、立地(駅から徒歩◯分とか)、床面積などがあげられますね。
で、それらの特徴量と目的値との関係を学習させていくと、その特徴量から目的値を予測することが可能になります。
ざっくり言うとこれが機械学習です。 (教師あり学習)

その特徴量を何にするか? が、機械学習の鍵、キモでありまして。
私が特徴量として使っているのは
- 競走馬の過去出走レース補正タイム指数(TARGET frontier JVから取得)
→前走、2走前、3走前、5走平均、10走平均、直近10走のMAX、同条件の過去レースの直近5走平均(競馬場、距離、馬場状態それぞれ)
- 競走馬の過去レース着順
→過去3、5走着順平均
- 各出走馬の種牡馬の競馬場、コース距離別実績(補正タイム指数の平均)
後はPCI(ペースチェンジ指数)を使って展開の有利不利を考慮してみたいなと思っていますが、まだそれは実装できていません。
特徴量としてではなく、展開(ハイペース or スローペース)を機械学習で予想するのも面白いかもしれません。
んで、目的変数はもちろんレースの結果(着順)ですね。
以上の感じでゴリゴリ機械学習かけてます。
機械学習のアルゴリズムは?
機械学習のアルゴリズムはいろいろあるんですけど、今最も流行り(?)のLightGBMを使っています。
LightGBMには順位、ランキングを予想するlambdarankというアルゴリズムがあります。これが競馬の機械学習には最もとっつきやすいアルゴリズムじゃないかなと思います。
まあ、LightGBMは学習スピードがめちゃくちゃ早くて、テキトーな特徴量突っ込んでもそれなりの精度の予想結果を返してくれるイケてるやつですね。
今回はまあざっくり概要だけですが、将来的に学習モデルが固まったら詳細を公開するかもしれません。
今はまだ試行錯誤の状態ですので。
予想モデルの検証結果
まさかの単勝回収率100%超え?
で、気になるその機械学習モデルではじき出した予想の検証結果はというと・・・
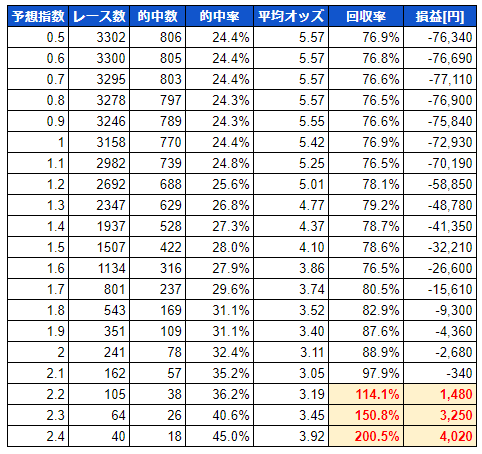
これは中央競馬の2021年1月1日~2022年1月30日の間の13ヶ月のレースを対象(戦績がゼロの新馬戦と障害戦を除く)とした予想の結果です。
一番左の予想指数なんですが、これはランク学習をした際に出力される指数と考えてください。つまり、同一レース内でその指数が一番高い馬が1着になる可能性が高いと予想される・・・わけですね。
ただ、この指数ですが出走メンバーの格の違いのせいだと思うんですが、レースによって水準が全く違いまして、レースごとに偏りがあります。
これではレースごとの単純な比較ができないですし、同一レース内での指数の分布もバラバラで分析ができない。
というわけで、私はその指数を標準化したものを予想に使っています。それが予想指数です。
この表で予想指数1.0となっている行は、ランク学習で吐き出された指数(標準化)が1以上の1着予想の馬の馬券を勝った場合の結果と見てください。
一番右の損益は対象馬の単勝馬券を100円買った場合の収益です。
まあ、この結果を見て頂けると予想指数が高い馬ほど、的中率が高くなっているのが分かります。
2.2以上に至っては回収率が100%を超えておりますし・・・おおおぉぉぉ、こりゃあどえらいことじゃぁ と思わず興奮しちゃったんですけども・・・実はこれ後で説明しますけど、ちょっと微妙なんですよね。うむむ・・・
重要なのは出走メンバー同士の相対比較ですね
先の表は単純に予想指数が高い馬を勝った場合のシミュレーション結果ですが、重要なのは同一レース内での指数の比較ですよね。
例えば、1着予想の馬の指数が2.0と高くても2番手の馬が1.95と1番手に迫る指数を持っていたらどちらが勝ってもおかしくないわけで・・・
つまり、1番手と2番手の指数の差が大きければ大きいほど、1番手の馬の予想信頼度が上がるのでは? と考えるわけです。
というわけで、やってみましたシミュレーション。
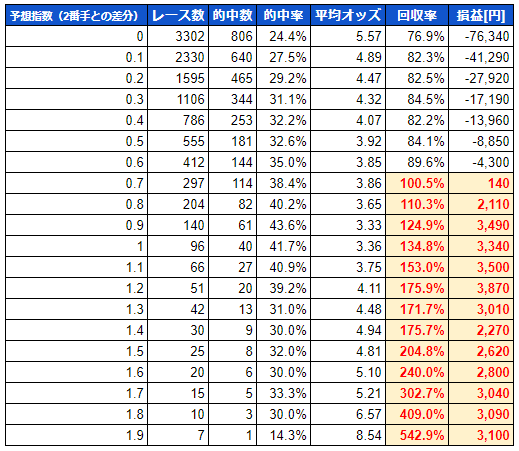
あ、あれ・・・
なんか回収率がとんでもない事になっているんですが・・・これやばくねぇっすか?
いやまて、落ち着け。というか、これまでの経験上、結果が良い方に出過ぎる場合、なんかどこかでやらかしているんですよね。こんな簡単に回収率出せるなら誰も苦労はしねぇっす。
それでまあ、冷静に考えてみると、普通1番手とその他の馬との実力差が開いていると機械学習モデルが予想すると、リアルでも人気になる傾向にあると思うんですよね。
ですが、このシミュレーション結果では、BETした馬の平均オッズがどんどん上がっている。おかしい。普通は下がるだろ?
ということで、2番手との差分が1.9以上のケースにて、唯一的中しているレースの詳細を見てみると
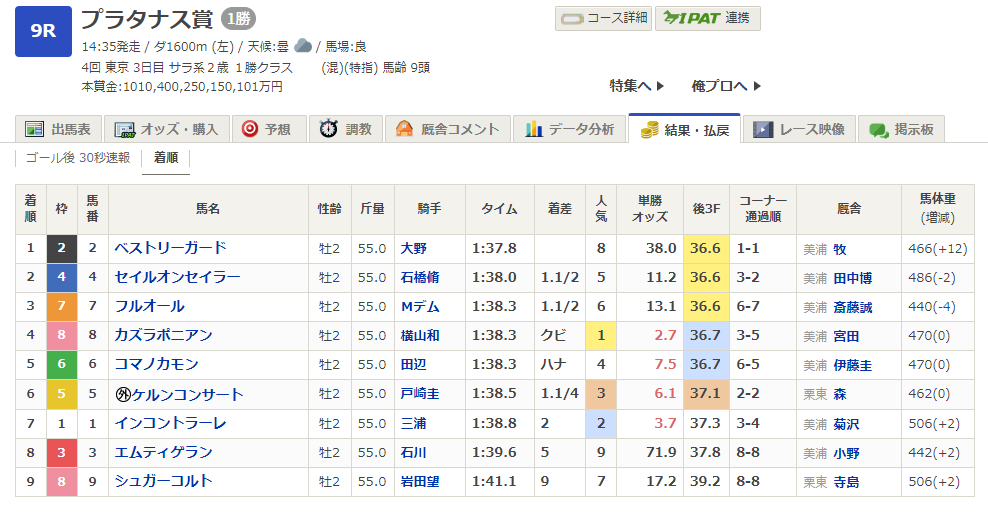
※レース結果画面はnetkeibaより
9頭立て8番人気の馬を的中させていました・・・
うん。そりゃ回収率上がりますわ。
とまあ、この1戦だけで、回収率、平均オッズが引き上げられていたんですねぇ・・・(´・ω・`)
たまたま当たっただけなのか 予想が当たったと見るべきか・・・
これは評価が微妙ですね。
この8番人気の穴馬について、たまたま当たっちゃったのか、きちんと予想して当たったのか・・・
2番手との予想指数の差分が大きい馬を買い続けたら、このシミュレーションと同じ結果が今後も得られるのか・・・
とはいえ、この手の予想はあまり楽観的に捉えるのはよろしくないと思うんですよね。なにしろお金がかかってますので!
私は、確実に利益が出るというシミュレーション結果がでない限りは安心できないんです( ー`дー´)
ぜんぜんダメダメというわけでもない
しかし、今回の結果ですが、全くのダメ・・・という事でもないと思います。
先の2番手との差分のシミュレーション結果ですが、1.4以上になると的中率が下がり始めています。
これは、確証はないですけど、実際のレースでは出走メンバーあまりに飛び抜けた実力の馬がいるケースは少ないと思うんですよ。
みんなクラスに合わせて出走しているわけですから。
で、機械学習モデルの予想で飛び抜けた指数がでたのは、なんかたまたま特徴量がうまい具合に噛み合っちゃた・・・というのがあるのではと(まったくの憶測)
しがたって、めちゃくちゃ高い数値が出ちゃったのは一種のバグで、高すぎても(差がありすぎても)信頼度が落ちるのではと・・・
対象となるレースも年間30しか無いし・・・、なんか異常なんですよ。きっとそうですよ。
自分で言ってて、そういう事があるのかなぁ・・・とは思うのですが、試しに差分が1.4以下のレースのみでシミュレーションした結果をドンッ
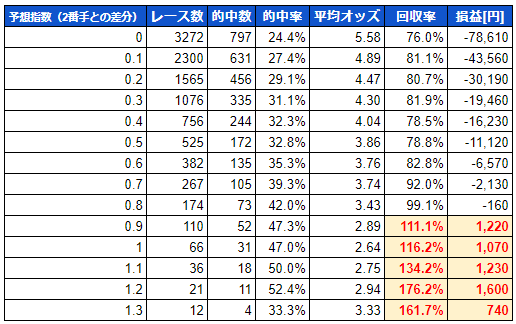
これは・・・対象レースがかなり絞られちゃいますが、かなりいい線いっているのではないでしょうか?(過信は禁物ですけど)
まあ、1.3も的中率が落ちているので1.2以下くらいが適正なのかな? と思いますが、その辺はいくつかシミュレーションの条件を変えて検証を続けたいと思います。
これ使えるの?
まあ、結局この予想モデルは使えるの? って話ですが、まああまり過信をしなければそこそこ使えるのではないか? と考えています。
2番手との差があればあるほど的中率が上がるという結果が示すとおり、予想の信頼性指標としては有用ではないかと思うんです。
まあ、まだまだ改良は続けますけどね。どこかでやらかしている可能性もありますし・・・(一番多いのが特徴量に未来情報が含まれているケースですねぇ、そこはかなり慎重に見ているんですけど)
とりあえず今週のレースはこの機械学習モデルの結果も交えて予想してみたいと思います。
・・・でも、あくまで馬券は自己責任にてお願いしますね。