前回のエントリー
-

統計ダッシュボードAPIでデータ取得 その2~スプレッドシートに書き込んでみる~
続きを見る
労働力調査のデータを取得するコードを公開
さて、前回GoogleスプレッドシートのAPIを使って、スプレッドシートに「Hello World!」と書き込むところまでやったと思いますが、私が作成した
統計ダッシュボードのAPIからデータを取ってきて、Googleスプレッドシートにデータを書き込むPythonコードを公開します。
まず一個目が統計ダッシュボードのAPIを叩くための関数を定義したコード
ファイル名:statdash.py
import pandas as pd
import requests
import urllib
import urllib.parse
def get_json(base_url, params):
params_str = urllib.parse.urlencode(params)
url = base_url+params_str
json = requests.get(url).json()
return json
def get_keiretsu(keiretsu_code, time):
base_url = "https://dashboard.e-stat.go.jp/api/1.0/JsonStat/getData?"
code = keiretsu_code[:19]
cycle = keiretsu_code[20]
tyousei = keiretsu_code[24]
if int(cycle) > 1:
if time:
params = {
"Lang": "JP",
"IndicatorCode": code,
"MetaGetFlg": "Y",
"Cycle": cycle,
"RegionalRank": "2",
"SectionHeaderFlg": "2",
"TimeFrom": time,
}
else:
params = {
"Lang": "JP",
"IndicatorCode": code,
"MetaGetFlg": "Y",
"Cycle": cycle,
"RegionalRank": "2",
"SectionHeaderFlg": "2",
}
else:
if time:
params = {
"Lang": "JP",
"IndicatorCode": code,
"MetaGetFlg": "Y",
"Cycle": cycle,
"IsSeasonalAdjustment": tyousei,
"RegionalRank": "2",
"SectionHeaderFlg": "2",
"TimeFrom": time,
}
else:
params = {
"Lang": "JP",
"IndicatorCode": code,
"MetaGetFlg": "Y",
"Cycle": cycle,
"IsSeasonalAdjustment": tyousei,
"RegionalRank": "2",
"SectionHeaderFlg": "2",
}
dataset = get_json(base_url, params)
time = pd.DataFrame(dataset["link"]["item"][0]["dimension"]["Time"]["category"])
value = pd.DataFrame(dataset["link"]["item"][0]["value"])
tani = dataset["link"]["item"][0]["dimension"]["Indicator"]["category"]["unit"]
unit = []
for i in tani.values():
unit.append(i)
time1 = time.reset_index(drop=True)
time_label = time1.drop("index", axis=1)
df = pd.concat([time_label,value], axis=1)
column_label = dataset["link"]["item"][0]["label"]
df1 = df.rename(columns={"label" : "時間", 0: column_label})
outputdata = df1.astype({column_label: float})
return outputdata, unit[0]["label"], column_labelで、二つ目が、労働力調査のデータを引っ張ってきて、Googleスプレッドシートに書き込む部分のpythonコード
ファイル名:労働力調査.py
import gspread
from oauth2client.service_account import ServiceAccountCredentials
import numpy as np
from statdash import get_keiretsu
# シートへの書き込み処理
def sheet(write_value, alpha, cont):
data_range = alpha + str(cont) + ':' + alpha + str(len(write_value) + cont - 1)
cell_list = wks.range(data_range)
for k, cell in enumerate(cell_list):
cell.value = write_value[k]
wks.update_cells(cell_list)
# 取得したいデータの系列要素コード
code = np.array([
[
'0301010000010010010010201',
'0301010000010020000010201',
'0301010000010120010010201',
'0301010000010120110010201',
'0301010000020010010010201',
'0301010000020020010010201',
'0301010000030010010010201',
'0301010001010010010010201',
'0301010001010020000010201',
'0301010001020010010010201',
'0301010001020020010010201',
'0301010001030010010010201',
'0301010002010010010010201',
'0301010002010020000010201',
'0301010002020010010010201',
'0301010002020020010010201',
'0301010002030010010010201',
], [
'0301010000010010010010202',
'0301010000020010010010202',
'0301010000020020010010202',
'0301010000030010010010202',
'0301010001010010010010202',
'0301010001020010010010202',
'0301010001020020010010202',
'0301010001030010010010202',
'0301010002010010010010202',
'0301010002020010010010202',
'0301010002020020010010202',
'0301010002030010010010202',
], [
'0301010000010010010020201',
'0301010000010020000020201',
'0301010000020010010020201',
'0301010000020020010020201',
'0301010000030010010020201',
'0301010001010010010020201',
'0301010001010020000020201',
'0301010001020010010020201',
'0301010001020020010020201',
'0301010001030010010020201',
'0301010002010010010020201',
'0301010002010020000020201',
'0301010002020010010020201',
'0301010002020020010020201',
'0301010002030010010020201',
], [
'0301010000010010010030201',
'0301010000010020000030201',
'0301010000020010010030201',
'0301010000020020010030201',
'0301010000030010010030201',
'0301010001010010010030201',
'0301010001010020000030201',
'0301010001020010010030201',
'0301010001020020010030201',
'0301010001030010010030201',
'0301010002010010010030201',
'0301010002010020000030201',
'0301010002020010010030201',
'0301010002020020010030201',
'0301010002030010010030201',
], [
'0301010000010120010030201',
'0301010000010120110030201',
]
])
# 取得する時系列データの開始年月
timefrom = ["20000100", "20000100", "20001Q00", "1990CY00", "1990CY00"]
# yyyymm00, yyyy1Q00, yyyy2Q00, yyyy3Q00, yyyy4Q00, yyyyCY00, yyyyFY00, 99999999
# 書き込むGooglespreadsheetのファイル名
sheet_name = '労働力調査_dash'
# 書き込むシートの名前
sheet_label = [
"月次",
"月次(季節調整)",
"四半期",
"年次",
"就業率年次"
]
alphabet = [chr(i) for i in range(65, 65 + 26)] # 大文字アルファベットのリストを作る
# Googleドライブ認証
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name('<JSONファイル名>.json', scope)
gc = gspread.authorize(credentials)
for y in range(len(sheet_label)):
wks = gc.open(sheet_name).worksheet(sheet_label[y])
# 時間軸書き込み
outputdata, unit, column = get_keiretsu(code[y][0], timefrom[y])
tokei = outputdata.fillna(0) # NaNを0に置き換える
series = tokei['時間'] # カラム「時間」でデータフレーム→シリーズ化
value = series.reset_index().values.tolist() # シリーズをリスト化する
counter = 0
sheet_value = []
for j in range(len(value)):
sheet_value.append(value[j][1])
sheet(sheet_value, alphabet[counter], 2)
counter += 1
# データ書き込み
for x in range(len(code[y])):
outputdata, unit, column = get_keiretsu(code[y][x], timefrom[y])
tokei = outputdata.fillna(0) # NaNを0に置き換える
series = tokei[column] # カラムでデータフレーム→シリーズ化
value = series.reset_index().values.tolist() # シリーズをリスト化する
sheet_value = []
for j in range(len(value)):
sheet_value.append(value[j][1])
sheet(sheet_value, alphabet[counter], 2)
counter += 1
改めてみると長いですね・・・
多分スキルのある人ならもっとスマートに書けるんだと思いますが、一応動いて目的のデータを取得できるんですからOKかなと思います。
目的は達成できているんだからヨシ! ・・・だよね?
処理の内容
あまり細かいところまで書くと長くなってしまいますので、大体の処理の流れを説明しますが、
↓この部分で、APIから取得したい労働力調査のデータを統計ダッシュボードの系列要素コードで指定しています。
# 取得したいデータの系列要素コード code = np.array([ [ '0301010000010010010010201', '0301010000010020000010201', '0301010000010120010010201', '0301010000010120110010201', '0301010000020010010010201', '0301010000020020010010201', '0301010000030010010010201', '0301010001010010010010201', '0301010001010020000010201', '0301010001020010010010201', '0301010001020020010010201', '0301010001030010010010201', '0301010002010010010010201', '0301010002010020000010201', '0301010002020010010010201', '0301010002020020010010201', '0301010002030010010010201', ]
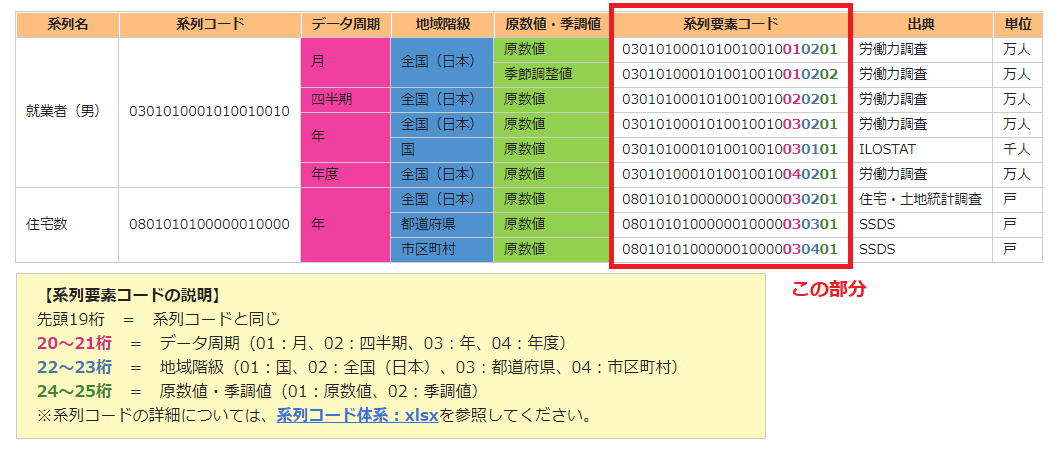
系列要素コードの詳細や、リストについては統計ダッシュボードのAPI概要ページを参照してください。
今回指定しているコードは労働力調査の以下の項目に当たるわけなのですが、
就業者(男女計), 就業率(総数), 就業率(15~64歳), 就業率(65歳以上), 完全失業者(男女計), 完全失業率(男女計), 非労働力人口(男女計), 就業者(男), 就業率(男), 完全失業者(男), 完全失業率(男), 非労働力人口(男), 就業者(女), 就業率(女), 完全失業者(女), 完全失業率(女), 非労働力人口(女)
これらのデータのそれぞれ 月次、月次季節調整値、四半期季節調整値、年次を取得するようにしています。
で、そのデータの開始年月はtimefromのリストで指定
# 取得する時系列データの開始年月 timefrom = ["20000100", "20000100", "20001Q00", "1990CY00", "1990CY00"]
このコードを実行するには、ファイル名「労働力調査_dash」のGoogleスプレッドシートをあらかじめ作っておく必要があります。
また、その「労働力調査_dash」のスプレッドシート内に "月次", "月次(季節調整)", "四半期", "年次", "就業率年次"のシートを作っておかないと動きません。
スプレッドシートが存在しない。もしくはシートがないと表示されて実行エラーになります。
# 書き込むGooglespreadsheetのファイル名
sheet_name = '労働力調査_dash'
# 書き込むシートの名前
sheet_label = [
"月次",
"月次(季節調整)",
"四半期",
"年次",
"就業率年次"
]もし、労働力調査以外のデータを取りたい場合は、上記のパラメータ(要素系列コードなど)を修正していただければ取得できます。
ま、自分仕様に作ったコードなので、慣れは必要だと思いますが・・・
あと必要なのはGoogleドライブ(スプレッドシート)の認証
# Googleドライブ認証
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name('<JSONファイル名>.json', scope)
gc = gspread.authorize(credentials)ここのJSONファイル名のところには前回のエントリーで取得したJSONファイルの名前(パス)を指定して下さい。
-
統計ダッシュボードAPIでデータ取得 その2~スプレッドシートに書き込んでみる~
続きを見る
これで認証が通ります。
あとは、実際のAPIを叩いて引っ張ってきたデータをスプレッドシートに書き込む処理がだらっと書かれています。
長くなるので説明は割愛します。読みずらいかと思いますが、、、ご容赦を。
コード実行
さっそくコードを実行します
$ python 労働力調査.py
実行するコードは二つ目の「労働力調査.py」だけでOK。
関数を定義している一つ目のコード「statdash.py」は同じ階層のフォルダに入れておいてください。
するとうまくいけば、ばばーんとデータが勝手にスプレッドシートに書き込まれるはずです。
こんなふうに
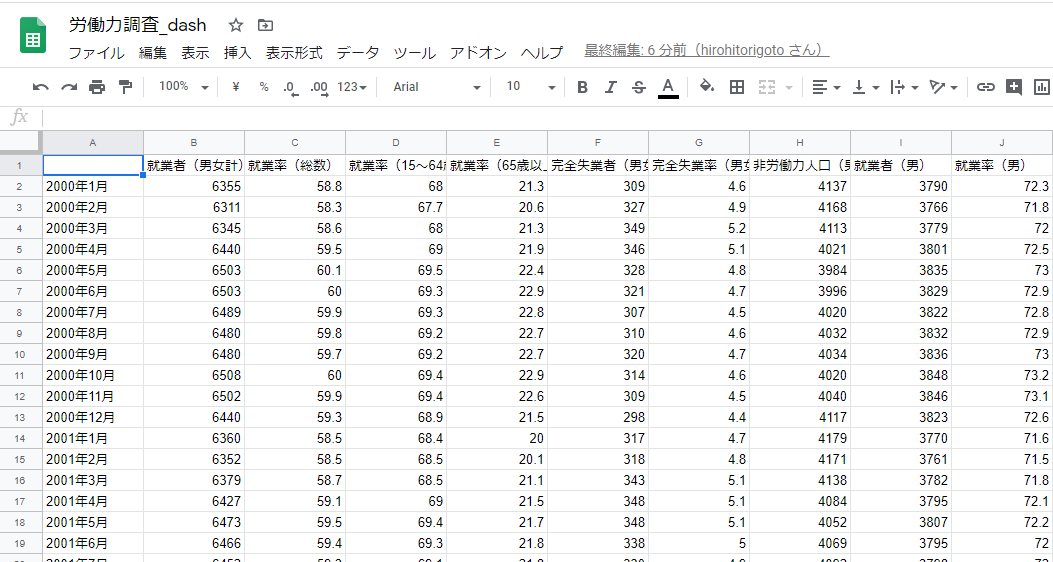
余談ですが、Pythonのスクリプトが走って、データがリアルタイムに書き込まれていく様を見るのはかなり気持ちがいいですw
あとは、Googleスプレッドシート上でグラフを描くなりすればOK。
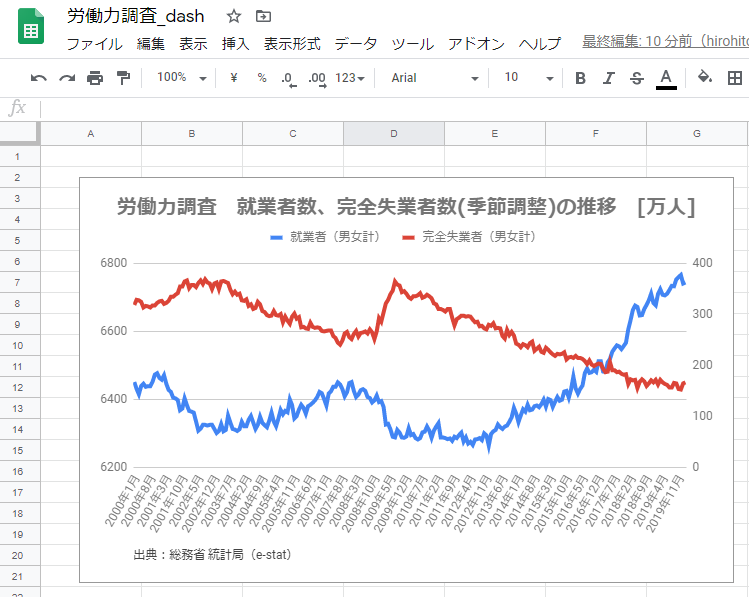
ね、簡単でしょ。
グラフをブログに張り付ける
さて、次は最後の仕上げ。
先ほど作ったグラフを、自分のブログに張り付ける作業です。
まず、貼り付けたいグラフの右上隅にある縦の3点リーダをクリックし、グラフを公開を選択
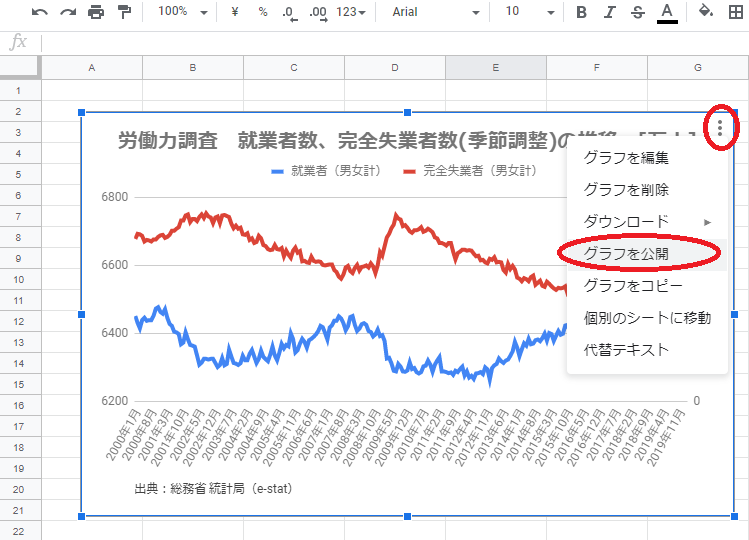
ウェブに公開するかどうか聞かれるので公開ボタンを押す
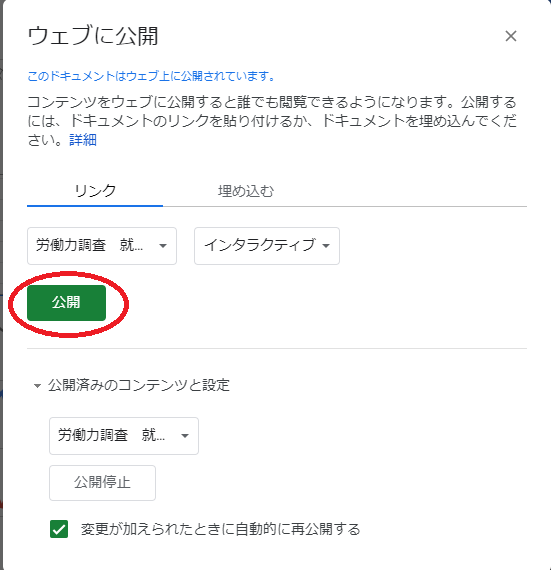
よろしいですかと聞かれるので、OKボタンを押す
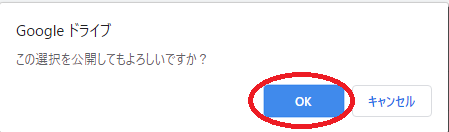
次に「埋め込む」のタブをクリックし、インタラクティブになっていることを確認して、枠内のコードをコピーします。
一応「変更が加えらえれたとき自動的に再公開する」にチェックが入っていることを確認してください。
ここにチェックがあると、スプレッドシート上で、データが書き換えられたとき、ブログに張り付けたグラフも自動的に更新されます。
便利ですよね。
あとはブログに張り付けるだけ
私はWordPressを使っているので、カスタムHTMLのブロックに先ほどコピーしたコードを貼り付けます

scrollingはyesに修正しておくことをお勧めします。
でないと、グラフが見切れた時にスクロールバーが表示されないので、グラフの全体が見えません。
で、実際に張り付けた結果がこれ
マウスカーソルを合わせると、インタラクティブに情報が表示されるのでかなりカッコいいですよね。
しかも、統計ダッシュボードのデータが更新されたら再度先ほどのpythonコードを実行すればグラフが修正されて、ブログ上のグラフも最新データに置き換わる。
かなり便利ではないでしょうか?
ま、今回は労働力調査のコードの紹介のみですが、このコードを書きかえれば他の統計ダッシュボードに掲載されているデータを引っ張ってくることは可能です。
よろしければチャレンジしてみてください。
次回は・・・
今回作ったグラフですが、一応Pythonスクリプトを走らせれば最新データに置き換わるわけなんですけど、更新するのにいちいちPythonスクリプトを手動で走らせるのはめんどくさい・・・
1個だけならできなくもないですが、何十個もスクリプトを作っちゃうとかなり厄介です。
そんなこと考えずに、一気全部に走らせればいいんじゃない?
と、思われるかもしれませんが、GoogleスプレッドシートのAPIは実は制限がありまして、無料versionだと、一定時間の間に実行できるAPIの回数が制限されています。
だから、ある程度間隔を空けて実行しなければAPIエラーになってしまい、スクリプトが途中で止まってしまいます。
というわけなので、それを解決し定期的にデータを更新するやり方をご紹介しましょう。
乞うご期待!